Bayesian Optimization with black-box constraints¶
Joachim van der Herten
Introduction¶
This notebook demonstrates the optimization of an analytical function using the well known Expected Improvement (EI) function. The problem is constrained by a black-box constraint function. The feasible regions are learnt jointly with the optimal regions by considering a second acquisition function known as the Probability of Feasibility (PoF), following the approach of Gardner et al. (2014)
In [1]:
%matplotlib inline
import matplotlib.pyplot as plt
import gpflow
import gpflowopt
import numpy as np
Constrained problem¶
First we set up an objective function (the townsend function) and a constraint function. We further assume both functions are black-box. We also define the optimization domain (2 continuous parameters).
In [2]:
# Objective & constraint
def townsend(X):
return -(np.cos((X[:,0]-0.1)*X[:,1])**2 + X[:,0] * np.sin(3*X[:,0]+X[:,1]))[:,None]
def constraint(X):
return -(-np.cos(1.5*X[:,0]+np.pi)*np.cos(1.5*X[:,1])+np.sin(1.5*X[:,0]+np.pi)*np.sin(1.5*X[:,1]))[:,None]
# Setup input domain
domain = gpflowopt.domain.ContinuousParameter('x1', -2.25, 2.5) + \
gpflowopt.domain.ContinuousParameter('x2', -2.5, 1.75)
# Plot
def plotfx():
X = gpflowopt.design.FactorialDesign(101, domain).generate()
Zo = townsend(X)
Zc = constraint(X)
mask = Zc>=0
Zc[mask] = np.nan
Zc[np.logical_not(mask)] = 1
Z = Zo * Zc
shape = (101, 101)
f, axes = plt.subplots(1, 1, figsize=(7, 5))
axes.contourf(X[:,0].reshape(shape), X[:,1].reshape(shape), Z.reshape(shape))
axes.set_xlabel('x1')
axes.set_ylabel('x2')
axes.set_xlim([domain.lower[0], domain.upper[0]])
axes.set_ylim([domain.lower[1], domain.upper[1]])
return axes
plotfx();

Modeling and joint acquisition function¶
We proceed by assigning the objective and constraint function a GP prior. Both functions are evaluated on a space-filling set of points (here, a Latin Hypercube design). Two GPR models are created. The EI is based on the model of the objective function (townsend), whereas PoF is based on the model of the constraint function. We then define the joint criterioin as the product of the EI and PoF.
In [3]:
# Initial evaluations
design = gpflowopt.design.LatinHyperCube(11, domain)
X = design.generate()
Yo = townsend(X)
Yc = constraint(X)
# Models
objective_model = gpflow.gpr.GPR(X, Yo, gpflow.kernels.Matern52(2, ARD=True))
objective_model.likelihood.variance = 0.01
constraint_model = gpflow.gpr.GPR(np.copy(X), Yc, gpflow.kernels.Matern52(2, ARD=True))
constraint_model.kern.lengthscales.transform = gpflow.transforms.Log1pe(1e-3)
constraint_model.likelihood.variance = 0.01
constraint_model.likelihood.variance.prior = gpflow.priors.Gamma(1./4.,1.0)
# Setup
ei = gpflowopt.acquisition.ExpectedImprovement(objective_model)
pof = gpflowopt.acquisition.ProbabilityOfFeasibility(constraint_model)
joint = ei * pof
Initial belief¶
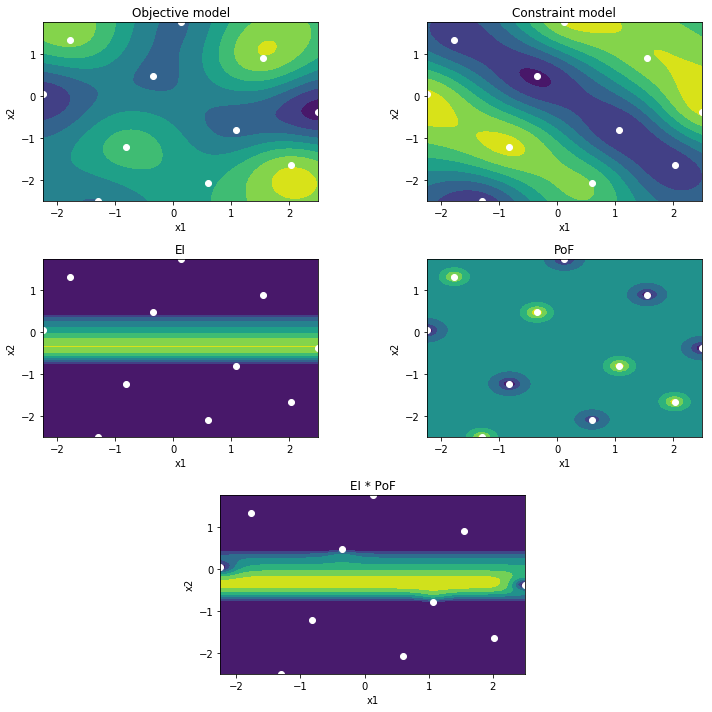
We can now inspect our belief about the optimization problem by plotting the models, the EI, PoF and joint mappings. Both models clearly are not very accurate yet. More specifically, the constraint model does not correctly capture the feasibility yet.
In [4]:
def plot():
Xeval = gpflowopt.design.FactorialDesign(101, domain).generate()
Yevala,_ = joint.operands[0].models[0].predict_f(Xeval)
Yevalb,_ = joint.operands[1].models[0].predict_f(Xeval)
Yevalc = np.maximum(ei.evaluate(Xeval), 0)
Yevald = pof.evaluate(Xeval)
Yevale = np.maximum(joint.evaluate(Xeval), 0)
shape = (101, 101)
plots = [('Objective model', Yevala), ('Constraint model', Yevalb),
('EI', Yevalc), ('PoF', Yevald),
('EI * PoF', Yevale)]
plt.figure(figsize=(10,10))
for i, plot in enumerate(plots):
if i == 4:
ax = plt.subplot2grid((3, 4), (2, 1), colspan=2)
else:
ax = plt.subplot2grid((3, 2), (int(i/2), i % 2))
ax.contourf(Xeval[:,0].reshape(shape), Xeval[:,1].reshape(shape), plot[1].reshape(shape))
ax.scatter(joint.data[0][:,0], joint.data[0][:,1], c='w')
ax.set_title(plot[0])
ax.set_xlabel('x1')
ax.set_ylabel('x2')
ax.set_xlim([domain.lower[0], domain.upper[0]])
ax.set_ylim([domain.lower[1], domain.upper[1]])
plt.tight_layout()
# Plot representing the model belief, and the belief mapped to EI and PoF
plot()
print(constraint_model)
WARNING:tensorflow:From c:\users\icouckuy\documents\projecten\gpflowopt\gpflowopt\acquisition\acquisition.py:362: calling reduce_prod (from tensorflow.python.ops.math_ops) with keep_dims is deprecated and will be removed in a future version.
Instructions for updating:
keep_dims is deprecated, use keepdims instead
name.kern.lengthscales transform:+ve prior:None
[0.18194828 0.14835351]
name.kern.variance transform:+ve prior:None
[0.63086542]
name.likelihood.variance transform:+ve prior:Ga([0.25],[1.])
[0.16823107]
Running Bayesian Optimizer¶
Running the Bayesian optimization is the next step. For this, we must set up an appropriate strategy to optimize the joint acquisition function. Sometimes this can be a bit challenging as often large non-varying areas may occur. A typical strategy is to apply a Monte Carlo optimization step first, then optimize the point with the best value (several variations exist). This approach is followed here. We then run the Bayesian Optimization and allow it to select up to 50 additional decisions.
The joint acquisition function assures the feasibility (w.r.t the constraint) is taken into account while selecting decisions for optimality.
In [5]:
# First setup the optimization strategy for the acquisition function
# Combining MC step followed by L-BFGS-B
acquisition_opt = gpflowopt.optim.StagedOptimizer([gpflowopt.optim.MCOptimizer(domain, 200),
gpflowopt.optim.SciPyOptimizer(domain)])
# Then run the BayesianOptimizer for 50 iterations
optimizer = gpflowopt.BayesianOptimizer(domain, joint, optimizer=acquisition_opt, verbose=True)
result = optimizer.optimize([townsend, constraint], n_iter=50)
print(result)
iter # 0 - MLL [-15.4, -16.4] - fmin [-1.21] - constraints [-0.916]
iter # 1 - MLL [-17.3, -17.7] - fmin [-1.21] - constraints [-0.916]
iter # 2 - MLL [-14.4, -12.7] - fmin [-1.21] - constraints [-0.916]
iter # 3 - MLL [-11.2, -13.4] - fmin [-1.54] - constraints [-0.778]
iter # 4 - MLL [-15.2, -14.5] - fmin [-1.54] - constraints [-0.778]
iter # 5 - MLL [-15.8, -14.6] - fmin [-1.63] - constraints [-0.615]
iter # 6 - MLL [-17.4, -14.8] - fmin [-1.63] - constraints [-0.615]
iter # 7 - MLL [-18.4, -14.4] - fmin [-1.63] - constraints [-0.615]
iter # 8 - MLL [-19.3, -15.1] - fmin [-1.63] - constraints [-0.615]
iter # 9 - MLL [-21.0, -15.2] - fmin [-1.63] - constraints [-0.615]
iter # 10 - MLL [-22.4, -15.1] - fmin [-1.63] - constraints [-0.615]
iter # 11 - MLL [-23.5, -15.2] - fmin [-1.63] - constraints [-0.615]
iter # 12 - MLL [-22.8, -14.3] - fmin [-1.63] - constraints [-0.615]
iter # 13 - MLL [-23.6, -14.9] - fmin [-1.88] - constraints [-0.921]
iter # 14 - MLL [-24.7, -15.7] - fmin [-1.88] - constraints [-0.921]
iter # 15 - MLL [-25.8, -16.2] - fmin [-1.88] - constraints [-0.921]
iter # 16 - MLL [-25.5, -15.3] - fmin [-1.88] - constraints [-0.921]
iter # 17 - MLL [-26.4, -15.1] - fmin [-2.3] - constraints [-0.889]
iter # 18 - MLL [-26.5, -15.2] - fmin [-2.65] - constraints [-0.567]
iter # 19 - MLL [-25.5, -15.3] - fmin [-2.85] - constraints [-0.393]
iter # 20 - MLL [-24.7, -15.4] - fmin [-2.96] - constraints [-0.299]
iter # 21 - MLL [-26.2, -18.3] - fmin [-2.96] - constraints [-0.299]
iter # 22 - MLL [-26.5, -17.1] - fmin [-3.17] - constraints [-0.493]
iter # 23 - MLL [-29.2, -18.2] - fmin [-3.17] - constraints [-0.493]
iter # 24 - MLL [-26.6, -15.9] - fmin [-3.18] - constraints [-0.64]
iter # 25 - MLL [-27.7, -16.5] - fmin [-3.18] - constraints [-0.64]
iter # 26 - MLL [-29.1, -18.1] - fmin [-3.18] - constraints [-0.64]
iter # 27 - MLL [-29.9, -18.7] - fmin [-3.18] - constraints [-0.64]
iter # 28 - MLL [-31.0, -18.6] - fmin [-3.18] - constraints [-0.64]
iter # 29 - MLL [-32.3, -19.6] - fmin [-3.18] - constraints [-0.64]
iter # 30 - MLL [-34.1, -18.8] - fmin [-3.18] - constraints [-0.64]
iter # 31 - MLL [-28.8, -14.1] - fmin [-3.2] - constraints [-0.571]
iter # 32 - MLL [-29.7, -14.2] - fmin [-3.2] - constraints [-0.571]
iter # 33 - MLL [-26.8, -10.7] - fmin [-3.2] - constraints [-0.571]
iter # 34 - MLL [-27.2, -11.0] - fmin [-3.2] - constraints [-0.571]
iter # 35 - MLL [-27.2, -11.9] - fmin [-3.2] - constraints [-0.571]
iter # 36 - MLL [-24.9, -9.19] - fmin [-3.2] - constraints [-0.571]
iter # 37 - MLL [-19.0, -3.94] - fmin [-3.2] - constraints [-0.571]
iter # 38 - MLL [-18.5, -3.12] - fmin [-3.2] - constraints [-0.571]
iter # 39 - MLL [-19.8, -3.26] - fmin [-3.2] - constraints [-0.571]
iter # 40 - MLL [-21.5, -2.7] - fmin [-3.2] - constraints [-0.571]
iter # 41 - MLL [-22.1, -1.64] - fmin [-3.2] - constraints [-0.571]
iter # 42 - MLL [-22.6, -0.981] - fmin [-3.2] - constraints [-0.571]
iter # 43 - MLL [-26.5, -4.06] - fmin [-3.2] - constraints [-0.571]
iter # 44 - MLL [-26.5, -3.61] - fmin [-3.2] - constraints [-0.571]
iter # 45 - MLL [-25.5, -1.62] - fmin [-3.2] - constraints [-0.571]
iter # 46 - MLL [-26.3, -1.42] - fmin [-3.2] - constraints [-0.571]
iter # 47 - MLL [-27.8, 0.0245] - fmin [-3.2] - constraints [-0.571]
iter # 48 - MLL [-28.4, 0.894] - fmin [-3.2] - constraints [-0.571]
iter # 49 - MLL [-25.9, 3.7] - fmin [-3.2] - constraints [-0.571]
constraints: array([-0.57055951])
fun: array([-3.19946737])
message: 'OK'
nfev: 50
success: True
x: array([[-2.25 , -1.29638397]])
Results¶
If we now plot the belief, we clearly see the constraint model has improved significantly. More specifically, its PoF mapping is an accurate representation of the true constraint function. By multiplying the EI by the PoF, the search is restricted to the feasible regions.
In [6]:
# Plotting belief again
print(constraint_model)
plot()
name.kern.lengthscales transform:+ve prior:None
[0.44676004 0.4866224 ]
name.kern.variance transform:+ve prior:None
[8.70831234]
name.likelihood.variance transform:+ve prior:Ga([0.25],[1.])
[1.96119947e-06]

If we inspect the sampling distribution, we can see that the amount of samples in the infeasible regions is limited. The optimization has focussed on the feasible areas. In addition, it has been active mostly in two optimal regions.
In [7]:
# Plot function, overlayed by the constraint. Also plot the samples
axes = plotfx()
valid = joint.feasible_data_index()
axes.scatter(joint.data[0][valid,0], joint.data[0][valid,1], label='feasible data', c='w')
axes.scatter(joint.data[0][np.logical_not(valid),0], joint.data[0][np.logical_not(valid),1], label='data', c='r');
axes.legend()
Out[7]:
<matplotlib.legend.Legend at 0x1b941465dd8>

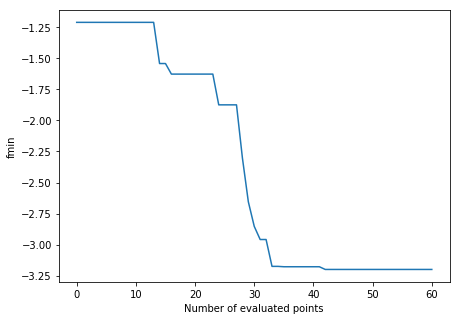
Finally, the evolution of the best value over the number of iterations clearly shows a very good solution is already found after only a few evaluations.
In [8]:
f, axes = plt.subplots(1, 1, figsize=(7, 5))
f = joint.data[1][:,0]
f[joint.data[1][:,1] > 0] = np.inf
axes.plot(np.arange(0, joint.data[0].shape[0]), np.minimum.accumulate(f))
axes.set_ylabel('fmin')
axes.set_xlabel('Number of evaluated points');
In [ ]: